

On February 25, 2026, Recursion reported business updates and financial results for its fourth quarter and full year ending December 31, 2025. In a related Earnings Call, Recursion CEO and President Najat Khan and Chief Financial Officer Ben Taylor shared details on the company’s latest partnership milestones, pipeline achievements, platform advancements, and financial results. Below, the full transcript from the Earnings Call.
Good morning, everyone, and thank you so much for joining us. I want to start by briefly framing where Recursion is today in its journey and evolution. Over the past decade, Recursion has built something truly special, a differentiated platform, pioneering the integration of large-scale biological data generation, machine learning, and compute to better understand the complexity of biology.
We have also deliberately strengthened the foundation in chemistry and AI through the acquisitions of Excientia, Valence Labs, and Cyclica, creating a truly powerful foundation. Today, we're at an important inflection point.
We're harnessing everything that we've built to date to do two things. Number 1, translating insights into evidence. Evidence that this platform, the use of AI end to end, can generate medicines that matter. And we're doing this both across our wholly owned portfolio and through our partnerships with strong momentum across both fronts.
I'm excited to share some of the updates today. In parallel, we're also continuing to advance the platform itself. You know, today, we have what I like to call a trifecta that's required to make impactful medicines – AI-driven biology, AI enabled chemistry, and AI applied to clinical development. We continue to invest to ensure we're defining the standard for how AI is applied across the full life cycle of R&D.
As we look across the sector, we are encouraged by the broader momentum in the field, new models, new players, partnerships being announced, but the industry is clearly entering a new phase where value is being defined, not only by the models you build and the collaborations that are announced, but by actually translating those.
This is the hard work – into capabilities, into real application and measurable impact. The important question now is not only what you build, but what you can unlock.
And that's the chapter Recursion is in.
Our focus is on unlocking that value, using AI end-to-end consistently to generate better targets, better molecules, and advance programs faster with repeatability. The ultimate goal is to deliver medicines that matter. So this quarter reflects that focus. We're making progress across all fronts.
First, on the clinical side with our first positive proof of concept with FAP. On the partnership side, a 5th milestone with Sanofi, reflecting our growing joint portfolio, tackling highly challenging targets. We're excited to share more about that today. And the continued evolution of our end-to-end AI platform. And last, but certainly never least, disciplined execution, which is something we talked about at JPM which has now extended our cash runway into early 2028.
There's a lot to cover today, so with that, let's jump right in.
We'll be making some forward-looking statements on this call, so please refer to our filings for more information. We always at Recursion start with the end in mind.
For us, like I said before, it's medicines that matter, that are truly differentiated. But in order to do that, you have to use the right data, models, compute, and more. There's a lot of talk about data, but what really matters is data that's high quality and fit for purpose.
At Recursion, our foundation has been building high-quality data at scale, not just one type of data sets, but multimodal across the board. This is where pioneering the lab in a loop, hiring, pioneering the wet and dry lab has become incredibly important so that we not only generate data, but then we generate purpose-built models that we test, learn, and improve.
The other thing I want to say is we sit in a sweet spot of being able to leverage both public data and our proprietary private data. That's incredibly important to ensure that our models are impactful, insightful, and unique. Also, the importance of not just having the ingredients, but actually having a team who knows how to use it well, teams that are bilingual, fluent in science and in AI.
But I want to add a third lens. It's also important to have reps under your belt to know what good looks like, and having talented teams that have reps is one of our core differentiators.
But the ultimate secret sauce, I will say, is how it all comes together. Having an integrated end-to-end operating system that is a continuous learning loop all the way from novel biology or novel insights through to the clinic. For many of us that have actually made medicines and have focused on this, which is a humbling effort, we all know that improving one decision in R&D is simply not enough. It's the compounded impact of better decisions across molecules, biological insight, all the way through the clinic, that is what makes the difference. That's how you truly change not just the outcome, but also the time and cost and how you do things, and that's what we are focused on at Recursion.
So what does that result in? First of all, in our clinical development, we have a diversified portfolio. We are very encouraged by our first AI-enabled clinical proof of concept with FAP, which has the potential to be a first in class for FAP, but we also have additional programs behind that.
In addition to that, in our discovery portfolio, we also have another diversified set of programs, and specifically, I'll just touch on the partner piece where we have brought in over half a billion in upfront and also milestones, and we'll share some additional updates today. I just want to say every single milestone we achieve not only improves the economics, but it's also a validation of the platform and a validation that we are learning fast in terms of what works, what doesn't to make our platform ever more intelligent.
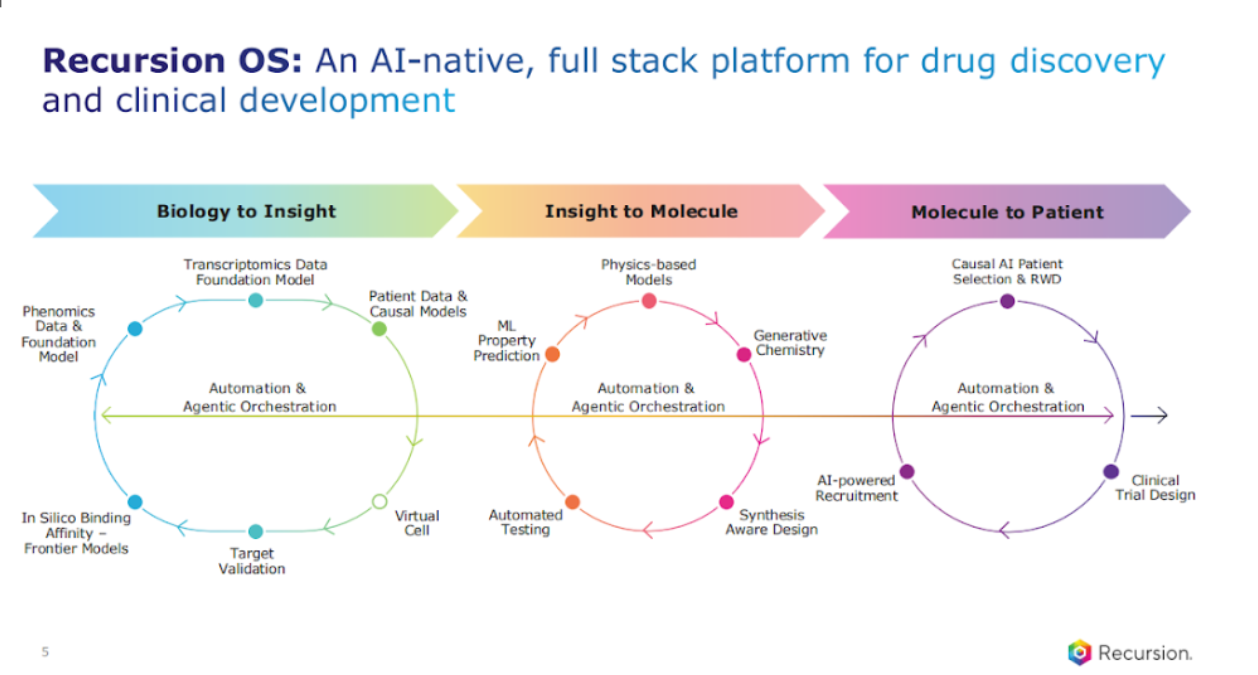
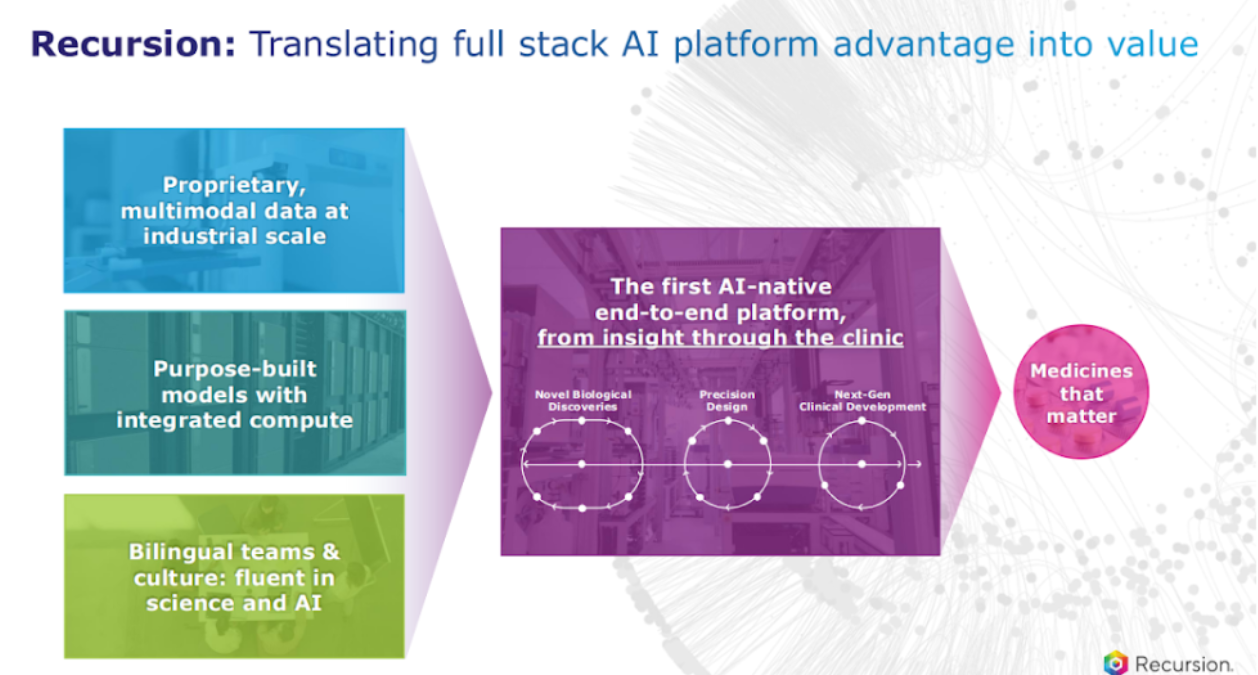
Let's talk about the platform. I’m going to share this slide every time we have an earnings call because this is so core to what we do.
Number one, being end to end, like I said before, is critical. You have to connect biology, chemistry, to, ultimately, the patient, which is really where the rubber hits the road. That's where we are going.
The other thing I also want to say is it's important to innovate, not just on data generation, but also your models. So, we have state of the art foundation models, not just in phenomics, but transcriptomics, and pulling those together in emerging virtual cell efforts that we're also focused on. We are also continuing to innovate on additional frontier models in the chemistry space as well as our newly built clinical development AI platform.
Again, it is that integration and how you harness it to unlock value that matters the most.

In terms of our strategic pillars, we have 3 main areas that we're doubling down on in this new chapter. Number 1, tangible proof points. This is so important, both from our clinical portfolio as well as our partner programs.
Second, in parallel, continuing to invest surgically in our platform, grounded in areas that will enable us to have more of those proof points.
And third, but certainly not the least, pairing that bold ambition that we have with discipline, execution, how do we do more with less?
So let's go through each of these. One area that's really important for us is we like to track what are our wins and learnings as we go through each of these pillars.
Our first pillar is really focused around making progress around the clinical pipeline as well as our partner programs. First, FAP, you know, this is really, really important data for a disease that has no approved therapies to date – durable and meaningful poly burden reduction.
Second, today we'll highlight our Sanofi collaboration, just as a reminder, this is where we're tackling challenging targets in I&I and oncology and leveraging our AI chemistry component of our platform to design novel compounds. And here, we just achieved our 5th milestone to date.
This is an example of the repeatability of our platforms, especially around using AI to develop chemistry molecules and small molecules.
The second pillar is really focused on our platform, and I want to highlight two things here.

As we look across the portfolio, we look at green shoots, as I like to call it, proof points, where we're actually seeing that we can do things better and faster.
So, one example is again, in our AI enabled chemistry platform. When we look across the portfolio, we're synthesizing 90% pure compounds than what we see in industry, so about 300 versus 2,500 compounds synthesized. This is because we are predicting more and making less.
This is where in silico approaches should be guiding us, and we're seeing that happen, and we're doing this 2 times faster.
So instead of it taking us, as in the industry, 42 months, we're seeing on average it takes us 17 months. We're going to keep pushing on this.
The other area, let's talk about biology. We talk constantly about the amount of unknown biology and what we're trying to do is generate, and we have generated first in industry, maps of biology, these huge atlases where we are trying to uncover unknown biology. This is in partnership with our great partners at Roche Genetic, two back-to-back maps that were just accepted, and now the team is hard at work in translating those maps into novel biological programs.

And our third pillar, momentum with discipline. Look, we have a lot of things we want to do, but we have to do it with discipline and good financial stewardship, financially, of course, but also operationally. And we're really excited to share that first of all, you know, we've seen a 35% reduction in pro forma operating expenses year over year.
This has come from multiple areas, sharper focus on our portfolio, yes, also optimizing our generative AI, improving our platform efficiency, in terms of the number of compounds we're synthesizing, our speed, etc.
The other thing that we're excited to share today is extending our runway to early 2028.
Let's dive into each of these pillars a little bit more, starting with our wholly owned pipeline.
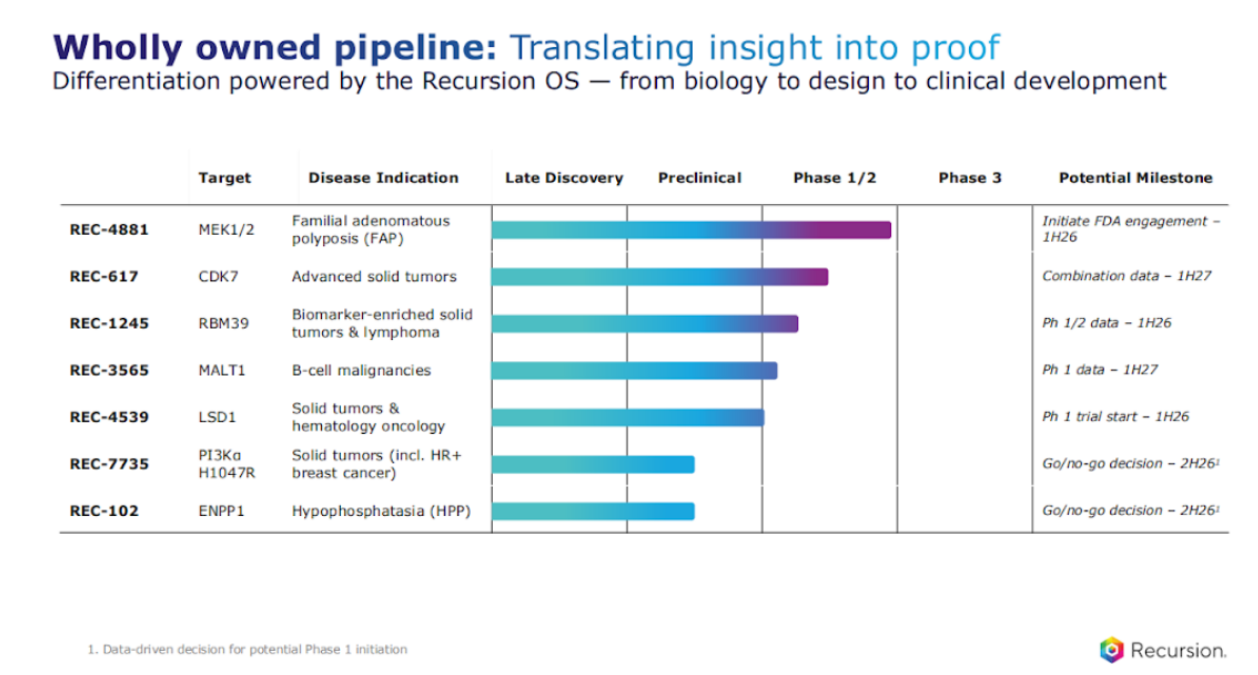
When we look at the number of programs here, we have a diversified portfolio. There are different types of differentiation across each of these programs, and I'm going to categorize it in three ways.
Number 1, there are programs with novel biological insight from our platform.
Number 2, there are programs that have emerging biology, interesting biology, which is unconquered, not validated yet, and we have developed optimized programs.
And then the 3rd is really focused around areas that have validated biology, but there's significant unmet need that still exists from a patient perspective.
So you've seen this slide before, we always track which components of our platform are we using across our various programs.
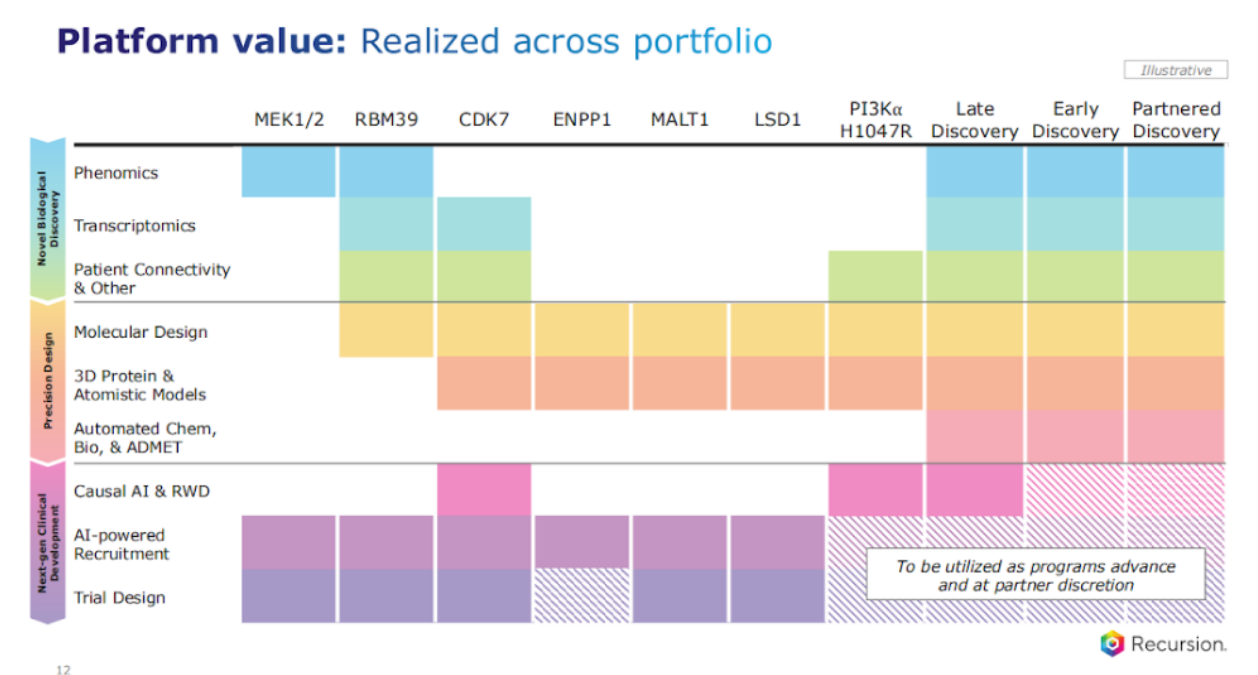
So let's dive into a little bit more around the three categories, starting with the platform-derived novel biological insight. Two programs that exist in that category, one, FAP, or REC 4881.
First of all, I don't need to say again, but the reason why there's such a significant unmet need, there's nothing approved for these patients. This is a disease that is hallmarked by hundreds of polyps, each and every one of which is pre-cancerous and has a 100% risk of CRC, colorectal cancer, by the time you're 40. More than 50,000 addressable patients in the US and EU.
The Recursion differentiation is using phenomics, the early version of the phenomics platform, to ascertain in an unbiased fashion that MEK1/2 inhibition could actually work in FAP.
We have just completed our Phase 2 study. We had a positive clinical readout which we just shared in December, and I'll share a little bit more about the data just to recap for those who might have missed it.
And one of our core next steps, and we're on track is to initiate FDA engagement on the registrational path in the first half of 2026. We also have another program that has similar elements from a differentiation perspective, RBM39.
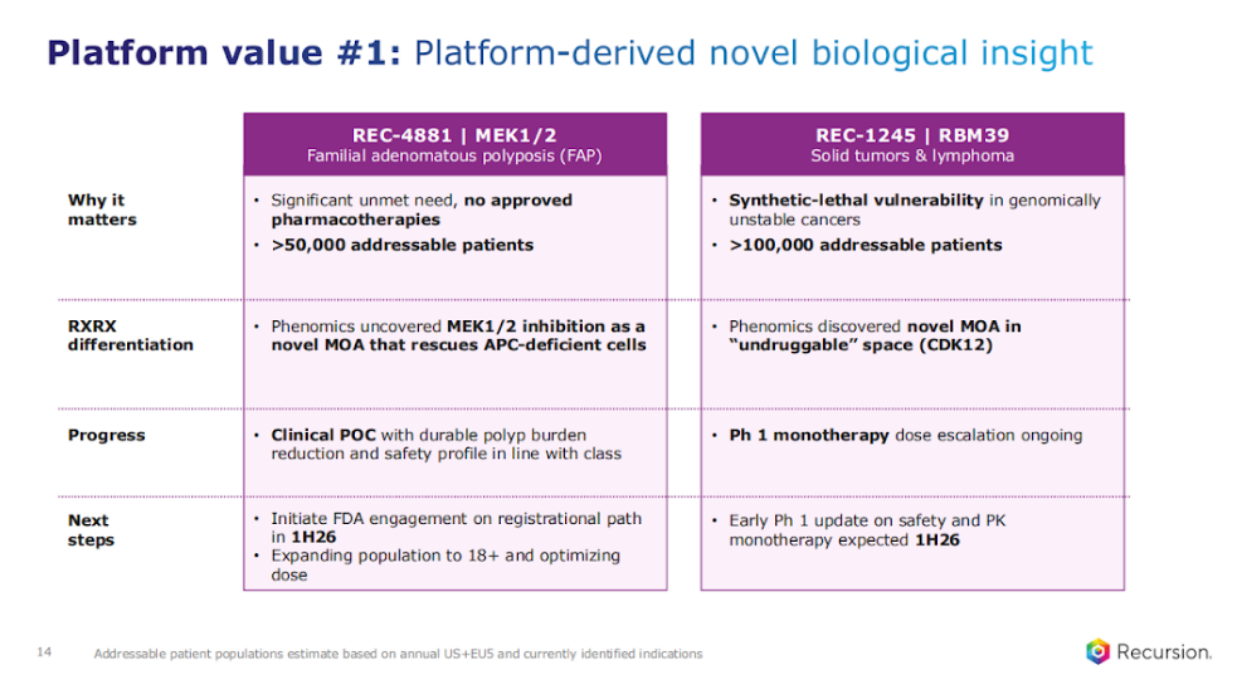
RBM39, look, is going to be potentially important in genomically unstable cancers, and from the patient population, as you can see that, that impacts a wide patient population. The differentiation for Recursion in our platform really came from uncovering this MOA and the connection it has to CDK12, which is known to be important for DDR (DNA damage response) modulation for many decades, but challenging to target because of the similar homology with CDK13. Right now, that program is in Phase 1 monotherapy dose escalation. And we expect to share an early phase one update on safety and PK first half of 2026, so later half of this year.
All right, let's go to the next category, emerging biology, that unconquered biology, and where we can optimize programs. There we have CDK7 and ENPP1, and you'll see what we're doing from an optimizing the program perspective is both on the chemistry side and also on the clinical development side.
Let's start with CDK 7. CDK7 has been known for a long time to be an important central master regulator, both of cell cycle control, but then also of transcription, which are, with a wide variety of patient populations that are addressable, given its centrality in oncology.

From a Recursion differentiation perspective, others have tried this target before, and one of the key challenges has been optimizing the PKPD, optimizing the therapeutic index.That's where we have leveraged the second element of our platform, AI chemistry, in order to optimize the molecules, especially around gut permeability.
We also are leveraging our platform in order to figure out which patient population to go into that could potentially benefit the most from CDK7 inhibition. Progress right now, we finished our Phase 1 monotherapy dose escalation, maximum dose has been selected, and we are in progress of the combination study, which is focused on ovarian cancer, second line, platinum resistant, with more data expected in the first half of 2027.
The next program that's also in this category is focused on ENPP1. ENPP1 loss of a certain mutation leads to challenges with bone mineralization, thereby leading challenges in, you know, fractures, pain, etc. Again, another lifelong disease that starts very early in the patient's trajectory, life trajectory.
The Recursion differentiation here is focusing on a molecule that can actually be oral because what's available today for patients and also some of the efforts in investigational agents is around enzyme replacement therapy that requires a huge burden for patient burden in terms of injections, subcutaneous, sometimes multiple a week.
So what we wanted to do is design a molecule for ENPP1, which again, challenging target, especially in this space for hyperphosphatasia, which can be suitable for chronic dosing. IND enabling studies are ongoing for this program right now, and we expect to have a go no go decision second half of this year on, on this program.
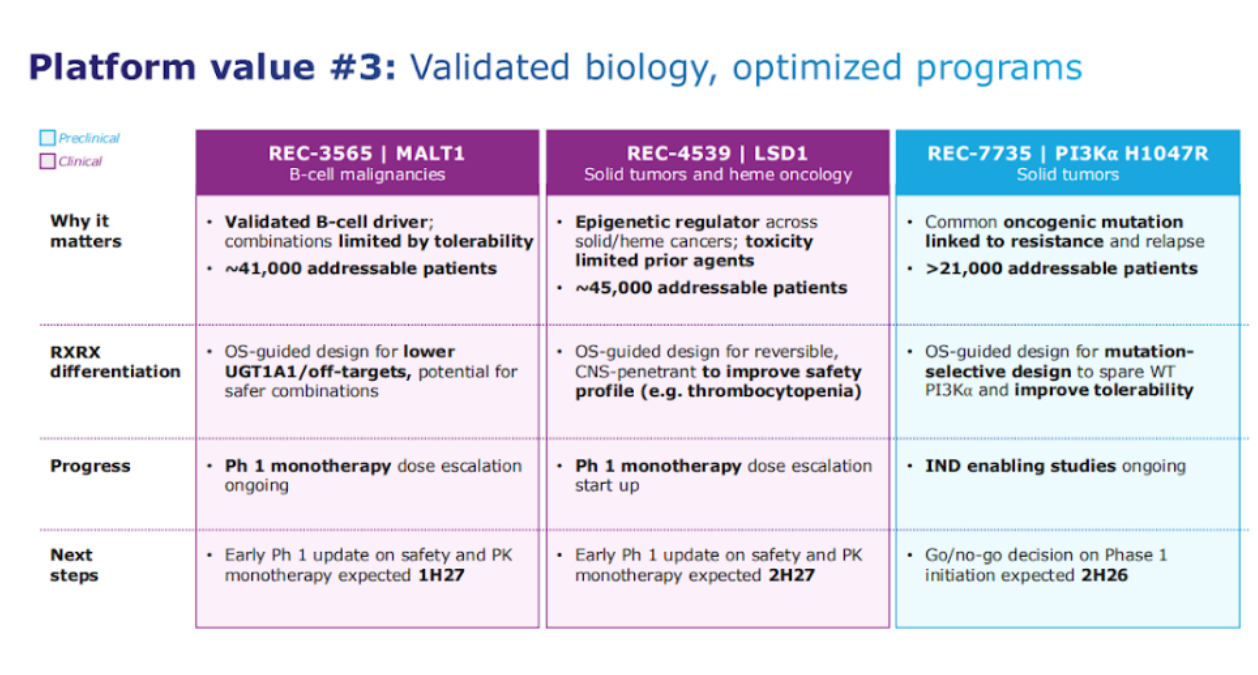
The third category are some of the targets that have validated biology but have significant unmet need that exists.
Let's take MALT1. MALT1 is validated from a target perspective in B cell drivers, but some of the challenges really have been around limitations around tolerability. So we again leverage our Recursion platform to really design molecules that could design away from some of the UGT1A1 and other targets that have been seen, which are gonna become increasingly important with combination with BTK inhibitors and others, which is what will be the ultimate efforts in this space.
So, we have phase one monotherapy dose escalation ongoing with early Phase 1 update data again on safety and PK monotherapy expected in the first half of 2027.
Another program that has a similar theme is LSD1. LSD1 is known to be an epigenetic regulator, really trying to prevent or inhibit some of the differentiation that you see in solid tumors such as small cell lung cancer and also AML with some validated data seen in AML recently.
And the differentiation again here is, can we design out some of the challenges around tolerability, which has led to some DLTs and not being able to dose up high enough, such as thrombocytopenia. This Phase 1 monotherapy dose escalation is starting, and next step is to have early Phase 1 update on safety and PK monotherapy expected in the second half of 2027.
Again, we expect to start to understand if some of the tolerability improvements we're trying to do, we can actually see that early on.
This is our theme around early go, no go decisions to really understand: is the design playing out in the clinic?
Another program that's in pre-clinical, and, late, late preclinical is our PI3K⍺ H1047R mutant selected. PI3K⍺ is an important oncogenic mutation linked to resistance and relapse, etc. I'll walk through a deep dive in terms of some of the latest data we have here, where again, remember, we use our platform to design a molecule that would be much, much more selective over 100 100x selectivity over wild type PI3K⍺ which leads to some of the tolerability challenges that leads to dose interruptions and reductions, and more to come there, but that's an I&D enabling study.
Again, go, no go decision, second half of this year expected, before we consider a Phase 1 initiation.
.png)
That was a trip around our portfolio, but I would love to actually double click on one of our later stage programs, REC-4881, and then also one of our earlier stage and potentially in entering our clinical pipeline, which is our PI3K⍺ program.
So, let's go through Rec-4881. I'm going to do a quick update for this program. We had our clinical POC (proof of concept) late last year. A couple of things to note – no approved therapies. What we saw in our Phase 2, 3 months on treatment with 4 mg qd of this MEK1/2 inhibitor, significant polyp burden reduction, about 43% median. One of the higher polyp burden reductions to date, 75% of the patients responded.
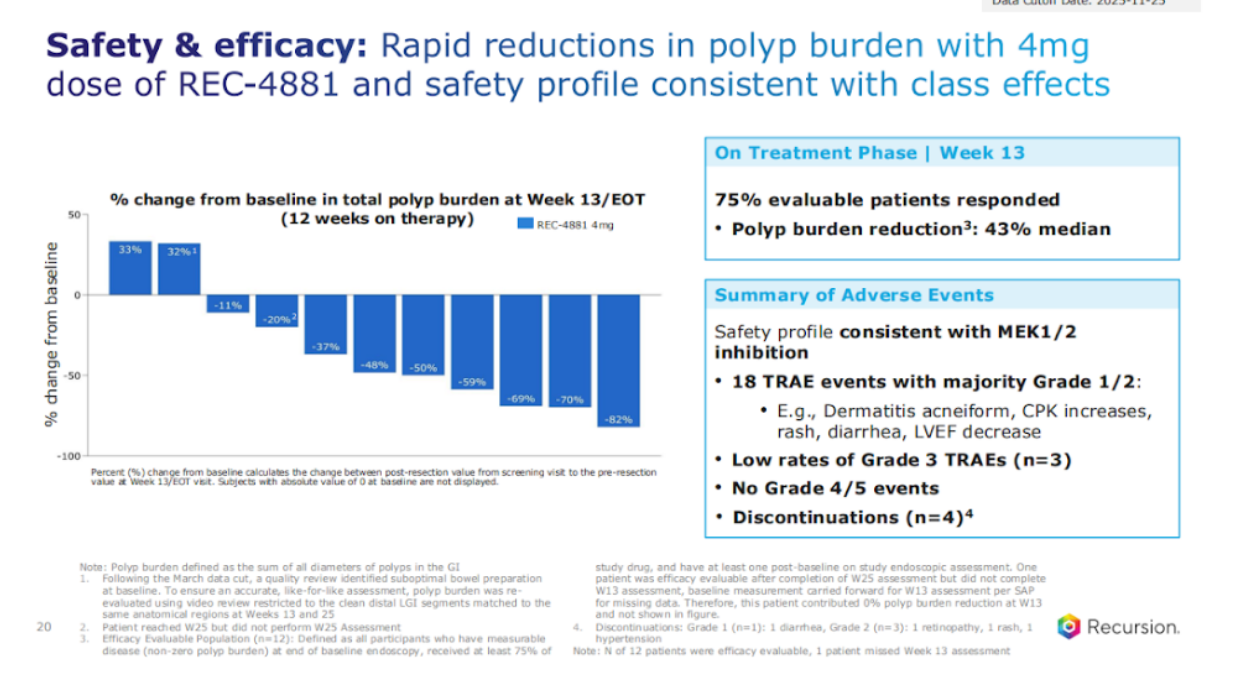
In terms of the AEs (adverse events) that we see, very much in line with what you see from MEK1/2 inhibitors, the majority were grade 1/2, rash, CPK, and no grade 4-5 to date. What we also saw, which was even more encouraging, was when these patients were then off treatment for 3 months, and remember, this is a chronic disease, so the on-off element is going to be really important for us to understand, we're the first, to actually look at on and off in, in this disease area, we see continued durable poly burden reduction in some cases actually deepening and with a significant amount of the patients actually responding.
So this is really important – to not just have insights, but how do you turn those into something that's meaningful for patients and then ultimately new medicines.
I won't recap in terms of the insight to proof point, but I'll focus on what's next. We're on track as we discussed late last year in terms of the FDA engagement initiating that first half of 2026 to really discuss the registrational study design. In addition to that, we've already started the enrollment of the 18 and over cohort. As you remember, some of the data we shared was for 55 and over, so we're already progressing on the 18 and over, and then also advancing dose optimization efforts, really inspired by what we saw with the durability data that I shared in the last slide.
We expect to have additional clinical data in the first half of 2027. So stay tuned, more to come.
Now, let's move to another exciting program that we have in our pipeline. This is our PI3Kα 1047 mutant selective. For PI3K, I'm sure you're thinking there are multiple PI3K. Why are we working on PI3K?
First of all, this is a very, very important target across multiple solid tumors. The current PI3K inhibitors have been constrained, and we have some data that we'll share shortly, Hyperglycemia, metabolic toxicity, dose interruptions, dose reductions, limited treatment duration, all of that means, is there an opportunity to do better by patients? There's an unmet need that still exists.

So what is our differentiation and what is our thesis, is really focusing on the 1047 mutant selective, which has 100x more selectivity over wild type, thereby having the potential to minimize risk for AEs (adverse events). In order to do that, we designed a molecule that can allow us to have that exquisite selectivity.
Let me just actually walk you through something that's very exciting from a platform perspective.
For this program, we started off with X-ray structures – that’s where we had proprietary structural insight. That led us to leveraging our MD simulations, and this is where compute becomes really important. Our molecular dynamic simulations revealed a novel pocket. We then use our generative 3D modeling efforts and, and machine learning in order to design molecules, novel scaffolds for this novel pocket, and we were able to use other ML approaches to rapidly design our cycles, so you get exquisite potency, but then also selectivity.
Remember, it is that selectivity that leads to the tolerability challenges we talked about.
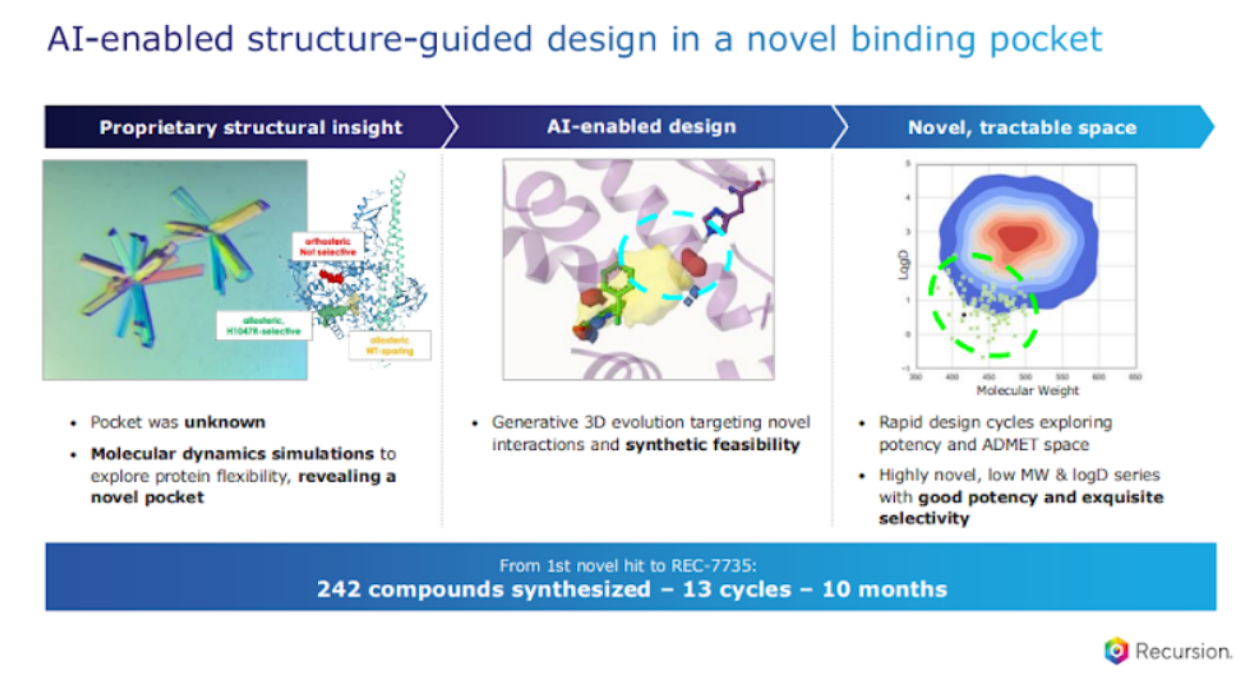
I want to take a moment, just look at the lower bar here, in order to design this compound. We designed 242 compounds, 13 cycles in 10 months. This is what we want to see from a green shoot perspective of the platform: Can you do it better? Can you do it faster? This is what we're tracking across our entire portfolio. I can tell you, compared to industry standards, this is fast.
And this is what gets us excited, data that we can actually do things better, faster.
The next question is, how does this molecule do? I'll share some pre-clinical data that we haven't shared before. First, let's look at how it does from a tumor reduction regression perspective. So if you look at the left-hand side over here, what you're looking at here is a dose-dependent tumor regression for a compound, as you, which is in blue.
And we actually also looked at some of the compounds that are in the market, such as Piqray and Scorpion’s compound, just to get a sense of how we're doing. And we see significant tumor regression, not just reduction, but regression with this compound. Comparable to what you see with Scorpion and much better than what you see with Piqray. But given the standard of care, we also wanted to see the performance versus standard of care. So, with SERD, with CDK 4-6 inhibitors, which is that comma is the standard of care today, and what's exciting to see here is the synergy.
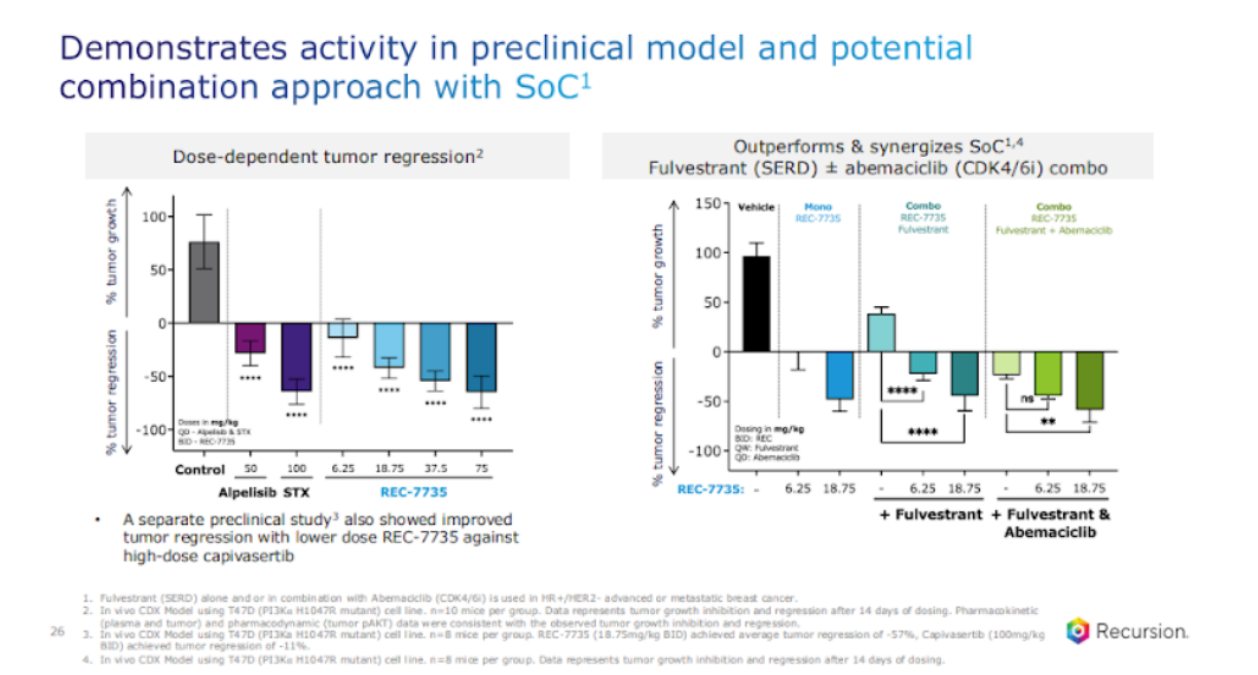
Monotherapy, yes, you see reduction and regression without compound, but you actually see synergistic efforts with the standard of care. This is very encouraging.
We actually have additional data, we only have so many charts we have space for, but we also looked at other encouraging assets in the space. And we saw improved tumor regression with low dose of our acid versus high dose cap. So all in all, this is encouraging from an efficacy perspective for this compound.
But then we also wanted to look at tolerability. So, here, what you're seeing is animal models for, from both naive wild type and then also obese diabetic animal models as well. On the left-hand side, you see, we don't see any impact on hyperglycemia markers in naive wild-type mice versus what you see with Scorpion and Piqray as well. Which is encouraging. This is what we are designing the molecule to do. And then if you go to the right side, a little bit complicated, but we like to share data.
Also, in obese diabetic rats, you don't see hyperglycemia or the metabolic liability even at supratherapeutic efficacious dose for our asset versus Scorpion and Piqray as well. So again, taken together, this is encouraging, but like I always say, the rubber hits the road in the clinic.
So what does this mean from a clinic perspective? Look, current PI3K inhibitors, you know, focusing on HR positive breast cancer, they do have tolerability limitations. You know, 65 to 85% experience hyperglycemia. Large percent actually also have dose interruptions, dose reductions, some of those driven by the hyperglycemia they're experiencing.
We also did some real-world analysis as well, given our clinical development AI platform, but really thinking about what the target product profile could look like, and you see the discontinuation about 3 to 6 months, and that's not a very long time.

So, I think the potential here, and we'll have to see A, how the compound does through IND-enabling studies, and that's where we are today. I can we expand that patient population in twofold. Number one, in breast cancer, not just in patients that are non-diabetic, but also patients that are pre-diabetic and diabetic, if this trajectory of hyperglycemia markers are not having impact holds. That's about 50% in breast cancer. And then the other is the broader patient population such as colorectal and endometrial, we can also explore.
One thing I'd be interested to also look at is can these patients because of the better tolerability, stay on longer treatment duration to really maximize the impact of these therapies. But again, clinical validation and improved tolerability is critical to confirm this expansion thesis.
So more to come. Again, we keep looking at these arcs. What was the insight? How did we design the molecule? What are the early proof points so far that you saw with pre, preclinical data, and what's next right now is the go no go decision for Phase 1, which would be the second half of this year. Currently, the study is in IND-enabling.
We'll also do a little bit more around our partnerships.
I'm really excited to share the progress we're making because remember, proof points can come from both your internal portfolio, which is what we just focused on, but then also from our amazing partners that we're working with on actual programs.
To date, we have already achieved over $500 million in total cash inflows from our partnership, both upfronts and milestones, and we've actually laid out some of those recent ones with the momentum that they, we've been achieving recently.
I want to emphasize something that sometimes gets lost, each and every one of the programs that we're working on has a potential for over $300 million in milestones and tiered royalty per small molecule program. Some of the royalties are up to double-digit royalties. So this is significant economics, and also a validation opportunity for Recursion.
We're very, very excited for the first time today to unveil our joint portfolio with Sanofi. Sanofi has been a fabulous partner. We learned so much from that exceptional team, both across I&I and oncology. And what we're showing here is the multiple programs that we're working on 5 and with multiple early discovery programs as well.
.png)
Just like our internal pipeline, this is also a diversified pipeline. It's focused on challenging targets in I&I and oncology, with molecules that have the potential to be first in class and or best in class. With programs that address very specific unmet needs. So thinking with the clinic in mind.
To date, we have advanced 5 lead packages that has been delivered by Recursion across 5 of these programs and accepted by Sanofi to date. That's $34 million in milestones to date, in addition to the $100 million in upfront, so $134 million so far. I just want to say, we have a lot of important work ahead of us with later stage discovery milestones over the next 18 months.
Look, discovery is probabilistic, you know, we know some will work and some of these programs won't, but it is the repeatability and the ability for our platform to have multiple shots on goal that's incredibly critical for us that's what you see with our internal portfolio that's what you see as we work humbly with our partners to also advance important programs for patients in areas that are challenging.
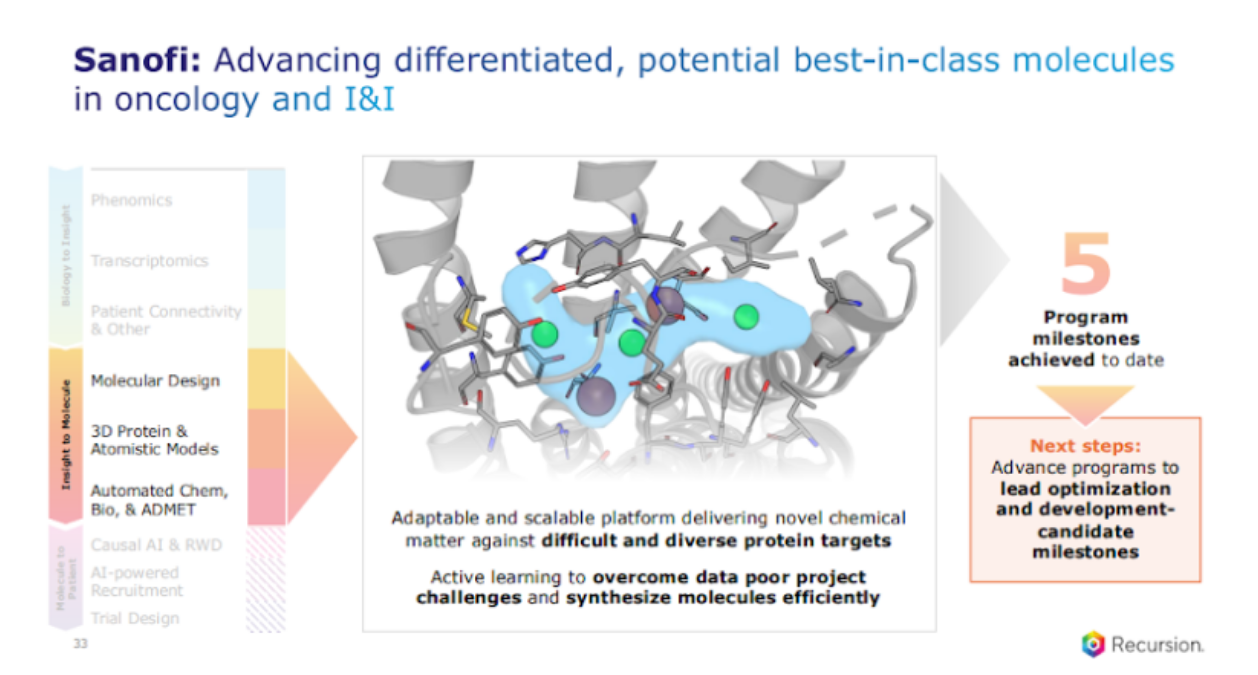
So just double clicking on one of these, you know, how do we get there? Remember, these are challenging targets and we are leveraging our platform, and I just want to explain one aspect that I think is really important. Our platform is not about one data, one model, one asset. It's about the confluence of a suite of them that you use for the problem at hand. So, we start with the problem first, and then you have flexibility and optionality across our models to get to the best outcome.
Our latest program, where we just got a milestone, our 5th milestone that we just achieved in the oncology program, really focused on leveraging these targets that are data poor. So we leverage both our physics-based approaches as well as our machine learning approaches, physics-based to really understand the protein flexibility better, find novel target, novel pockets, and then leverage our machine learning, algorithms in order to rapidly do our design-ma test cycle and find highly potent molecules, that are now progressing to the next stage. Very exciting progress here and stay tuned, more to come.
This is truly what proof points look like, actually showing value that will matter for the medicines that we are working towards. But none of this can happen without a unique and differentiated platform. That is an ever-important work in progress. So, I want to just do a snapshot of the three components of our platform, starting with biology to insight.
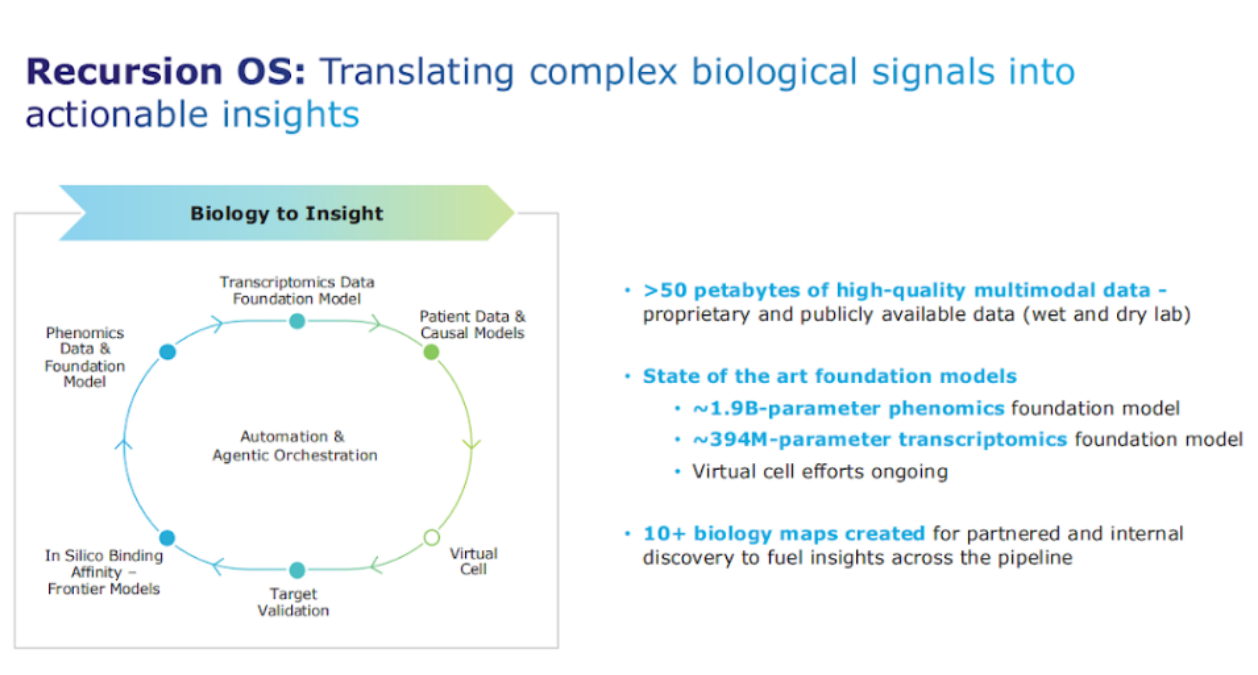
You know, I mentioned the proprietary data that Recursion has been building for a decade, 50 petabytes of high quality multimodal data, and I want to emphasize the multimodal piece. You know, biology is complex and having diversity of data and, you know, having at scale data sets complete to the extent possible – whole genome knockout, overexpression – that's the kind of multimodal data that you need to then build foundation models that are state of the art.
We have a fantastic team that's working on this, whether it's in the phenomics foundation models or the transcriptomic foundation models and it is the fusion of those models that is going to be really, really important in biology because we all know we need to connect input to output, genetics.
Transcriptomic, proteomic, phenomic, patient data, that's the effort that we're focused on, and how do we leverage it? That's the “so what.” What matters is creating these novel proprietary data sets. We call them biology maps, and, you know, we have those internally across different therapeutic areas.
We also have it in neuroscience and GI oncology with Roche and Genentech, and those insights are what's fueling our discovery pipeline.
The next area is focused on leveraging AI for chemistry, novel small molecules. I can tell you this is harder than it looks. We have used our in silico approaches to generate over 100 million molecules. You know, one emphasis, one point I want to emphasize is the point around synthetically aware design.
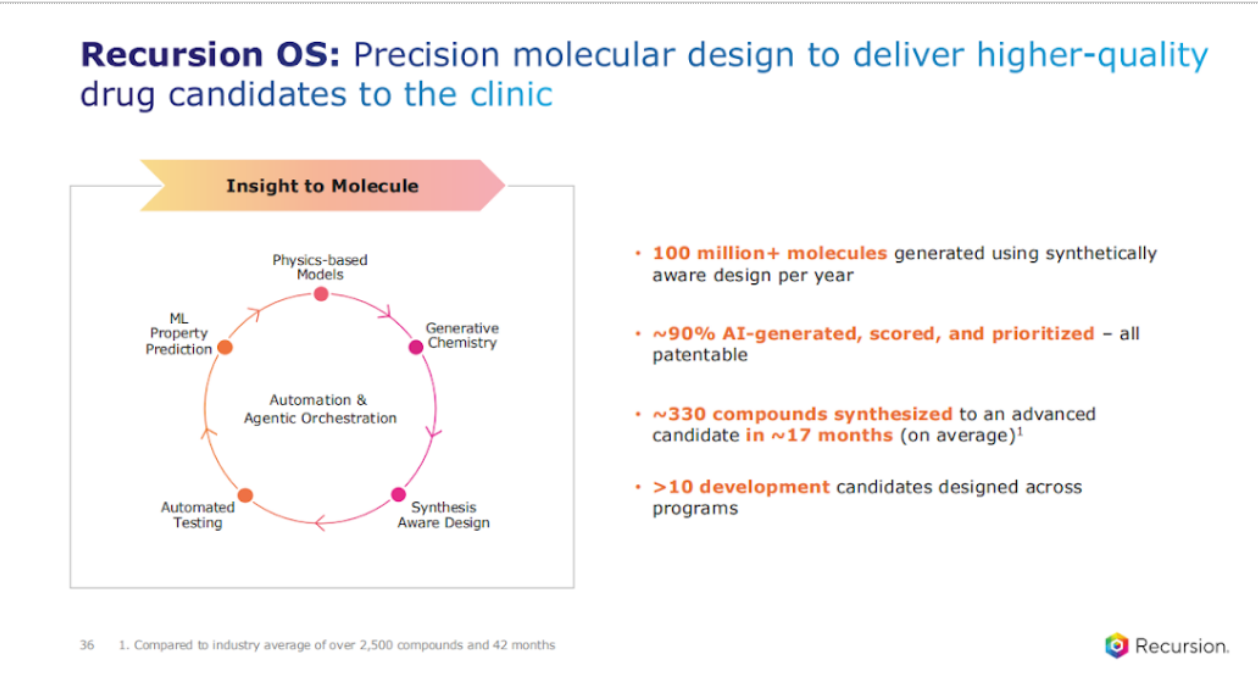
There's one thing to design molecules that are interesting, but if you cannot make them, then that limits, or if you can make them, but the CMC is very challenging, that really limits. We always start with that end in mind, the target product profile, what can be a true drug that matters.
We do that across our partnerships and our internal portfolio. Like I said before, 90% of these molecules are generated, or prioritized by our models. One thing that we're doing increasingly, not just leveraging automation, but also agentic orchestration, so we can get things done better, faster, and in a more unbiased approach.
And I mentioned the stat before, but I can't wait to mention it again. With PI3K, we made 242 compounds over 10 months, but across the portfolio, we like to be transparent around our data.
330 compounds is what we synthesize on average versus 2,500, or 5,000 in industry, and we do it in 17 months on average versus 40 months+ for industry.
These are the kinds of things that we track, and that's going from target all the way to advanced candidate. As a result, we have over 10 development candidates across our internal portfolio and are getting to that line with our internal and partner programs as well.
Last but certainly not the least, is an area that I get a lot of questions about – our newly built emerging clinical development AI platform. What we have done first, and again, just like we did with our biology platform and chemistry, you’ve got to build a really good data foundation, 300 million plus real-world lives, that's, you know, through both some internal work, but then also the great ecosystem, integrated data partnerships.

We're very opportunistic around that. Some of the early results, I mean, you can read the bullets here, but the one that I would point the attention to is enrollment rates.
In order to execute on programs, you have to enroll in a very efficient and intelligent way. And some of our early results for some of the programs, we're starting to see 1.3 to 1.6% improvement. We're also improving the operational piece that goes underneath it in terms of starting studies faster, by up to 3 months. All of this accumulates.
Remember the point around the compounding impact of decisions across the platform. This is how you define drug discovery and development, leveraging AI.
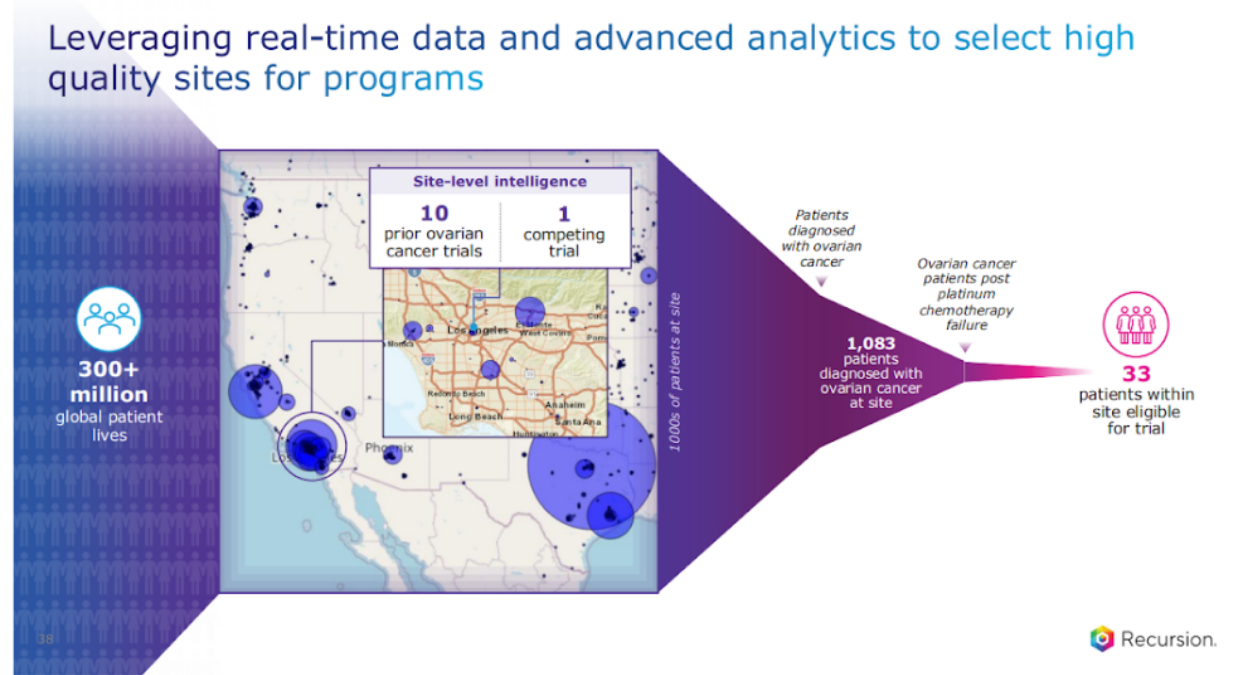
And let me just give you a sneak peek as to how that works on the enrollment front. So we start with the 300 million patient lives. Our platform can actually generate a heat map, just like you see for biology or chemistry, but here, for potential patients. And we're showing the US here, across the country, then we can go into deeper resolution at a state level, and then at a zip code, three-digit zip code level, and then at a site level. And what's really important here is we can also get data around the site's experience with running that trial, and this is, you can probably guess for which program, ovarian cancer, trials, and how many competing trials that exist, that becomes really important. You don't want to fish in the same pond, that can lead to delays.
Beyond that, we can also get how many patients these sites have, and then you can do a filter in terms of your inclusion exclusion and what's relevant for the type of patient that we are looking for in a specific study. That filter does not happen enough, I can tell you, in traditional approaches. We talk about precision medicine, precision biology, precision chemistry.
This is precision operations and starting with the patient in mind.
I want to now hand it over to Ben Taylor, our CFO, to go through some of our financials.
So, 2025 was a year of financial transformation for the company. As a part of the integration, we decided to rebuild all of our corporate systems from the ground up. This was really important because we wanted to be able to apply the same level of discipline and rigor to our strategic decision making that we do to all of our scientific decision making.

And so we looked at how every dollar in the company goes towards a specific quantifiable outcome. And that's how we were able to achieve the efficiencies that we did over the last year while still advancing up a portfolio of 5 clinical programs, hitting multiple different partner milestones, and really investing behind the growth in our platform as well.
All of that comes back to focus on those investments across our pipeline and technology portfolio that have the best risk return that are gonna give us the most impact for the investment that we're making. And so that's how we were able to come back and have a 35% year-over-year reduction from PRO (projected revenue outcome) for ‘24 to ‘25 and even come in 10% below the guidance that we originally provided in May of last year. So we ended the year with $754 million in cash.
Looking forward, our 2026 cash operating expenses are expected to be under $390 million.
Cash operating expenses is a non-gap measure that we're going to be using to give you guidance. We have a lot of non-cash expenses in our P&L and so we wanted to provide something that showed what our cash profile might look like going forward. So this is coming directly off of our cash flow statement.
If you look at operational cash flow, and then you add back our inflows from partnership and transaction costs, you'll be able to get directly to this guidance number that we're using.
In addition, last year, it was really exciting to see that we crossed the $500 million milestone in cumulative partner inflows. We expect to continue to achieve those, going forward. In fact, we hit our first milestone, earlier this month already. So we do include a probability weighting of some of those milestones in our cash flow projections going forward.
That's actually the really exciting part for me is not only were we able to exceed our efficiency expectations, but that actually means we need to extend out our cash runaway. So we're updating our guidance to go to early 2028 as of now.
And with that, I will hand it back over to Najat.
We'll wrap it up by just saying, looking ahead, we have a very broad set of catalysts that are coming up and it's going to be a busy next 18 to 24 months. In terms of, this year, we're on track for our initial engagement with the FDA on REC-4881. We're looking forward to that. And also initial data, early safety and PK for RBM39. And go no go decisions for PI3K and ENPP1, which are both in IND-enabling.

We'll also have additional data for REC-4881 early next year, and then combo data expected for our CDK7 program, as well as more early safety and PK data for MALT1 and LSD1. Recall, for both of those, we designed the assets to be more tolerable, so these are going to be important. And I know the partner catalyst looks like a small box here, but I wish I could physically expand it. Because that's going to be very important. Our partnership with Sanofi, as we just discussed, in terms of multiple programs as we're progressing into later-stage development candidates and other milestones as well. In addition to that, these maps where novel biology comes from, extracting that into new programs with Roche and Genentech.
So, really, really important work continues, and we continue to invest and push the boundaries in terms of our platform, defining what industry and standard really looks like for making medicines using AI. As Ben just mentioned, pairing all of that important work with disciplined execution.
We've really pivoted towards an outcomes-based budget where we test what every dollar what value creation, every dollar can drive, so doing more with less. I'll close by saying thank you so much for the time. And also, our focus will always remain on value creation for patients. They're the ones that we ultimately serve, patients are waiting, and also, of course, our shareholders.
Thank you again for listening.